Schauderbasis
JohannesI don't like adventure games

Point and Click adventure games (short “adventure games” from here on) are a genre of video games. They tell interactive stories, driven by puzzles. The most famous ones in my bubble are the monkey island series, the Edna & Harvey games and Day of the Tentacle.
…Wie man es schafft, dass Leute etwas tun

In dem Buch “Wie man es schafft, dass Leute etwas tun” steht, wie man Menschen (Kinder, Kollegen, Angestellte, Nachbarn, Sklaven, sich selbst…) dazu bringen kann, dass sie effizient an etwas Bestimmten arbeiten.
…Visualizing the tree of life

TLDR: I made a website about how different species are related: taxonomy.schauderbasis.de
…Geometrie im Sand

Archimedes soll ja seine geometrischen Beweise in den Sand gemalt haben. Ich habe das heute mal probiert und versucht, den Satz vom Fasskreisbogen zu beweisen.
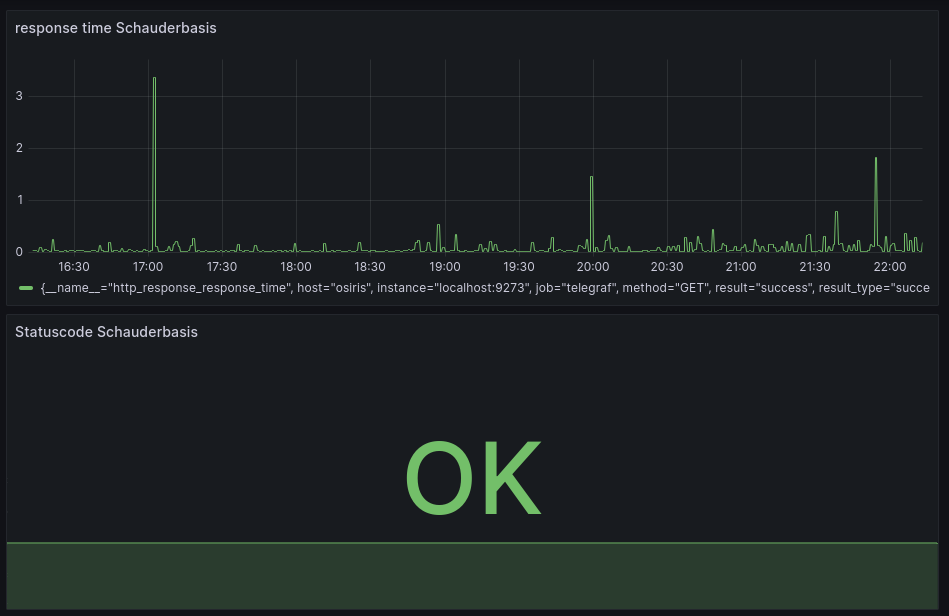
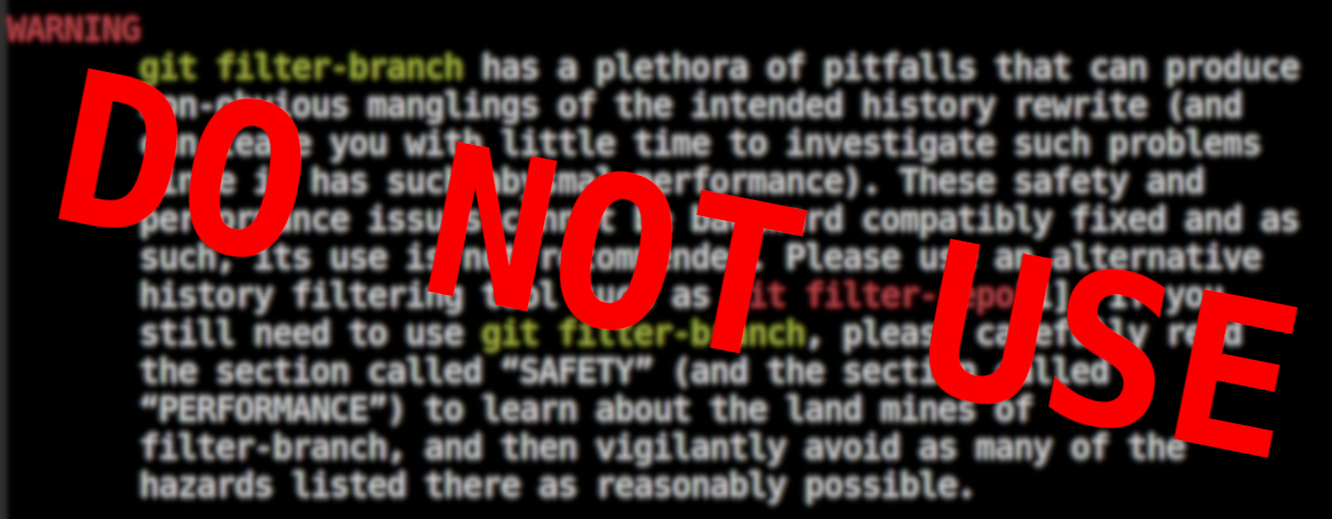
…Git Zeitstempel zensieren

Git Repositories enthalten jede Menge Informationen. Nicht nur über den Code, auch meta-informationen wie die Namen und Emailaddressen der Comitter. Solche Daten können durchaus sensibel sein - sie legen zum Beispiel offen…
…In einem Haus schellt das Telefon

Als ich ein Kind war hat meine Mutter mich dafür bezahlt, Gedichte auswendig zu lernen. Für meine Geschwister galt natürlich das gleiche Angebot. Sie wollte, das wir Gedichte kannten und das war ihr Weg, uns zu motivieren. Ich glaube es hat ganz gut geklappt, ich konnte einige Gedichte: Das Huhn und der Karpfen zum Beispiel, oder den Herr von Ribbeck auf Ribbeck im Havelland.
…Die vielen Worte um Kubernetes

Komplexe Themen lerne ich meistens erstmal nur so weit, wie es nötig ist. Nur so viel es braucht, um das Problem zu lösen. Das reicht meistens, ich muss ja auch verantwortungsvoll mit meiner Zeit umgehen. Mit Teilwissen kann man lange Zeit sehr weit kommen.
…Möwenweg reimt sich auf Bullerbü

Eine modernere Kinderbuchreihe
Die Bullerbü Bücher (von Astrid Lindgren) sind toll. Aber man vergisst keine Seite lang, dass es in der Vergangenheit spielt. Eine modernere Version ist die Reihe “Wir Kinder aus dem Möwenweg” (von Kirsten Boie).
…Bullerbü ist ein tolles erstes Buch

Ich liebe es, meinen Kindern vorzulesen. Die ersten Jahre funktionieren nur kurze Bilderbücher, die man in einem Rutsch durch bekommt. Aber bei 3 Jahren habe ich vorsichtig angefangen, längere Geschichten mit wenig Bildern für sie zu lesen, mit mehreren Kapiteln. Und das erste Buch war “Wir Kinder von Bullerbü”.
…Don't be a cynic

I was a cynic for most of my teenage years. One day my drama teacher labeled this behavior: “Ahhh, you are a cynic.” That one sentence made me reflect and realise that I didn’t really like that about myself. So I stopped.for a long time in school
…Changelog 4
I like the concept of those changelog posts. It makes me feel less pressure to write a full story and add pictures or so. It also gives me a better sense of progress.
…Changelog 3
Addressbook visualization came to a halt
Previously I had tried to visualize my address book as a graph. I stopped when I noticed that the vcf export I had didn’t include the photos. This was a problem of the address book app I use on my phone, so I filed a bug report. This stopped my momentum to work on the project for the moment.
…winner of the first IOPCC
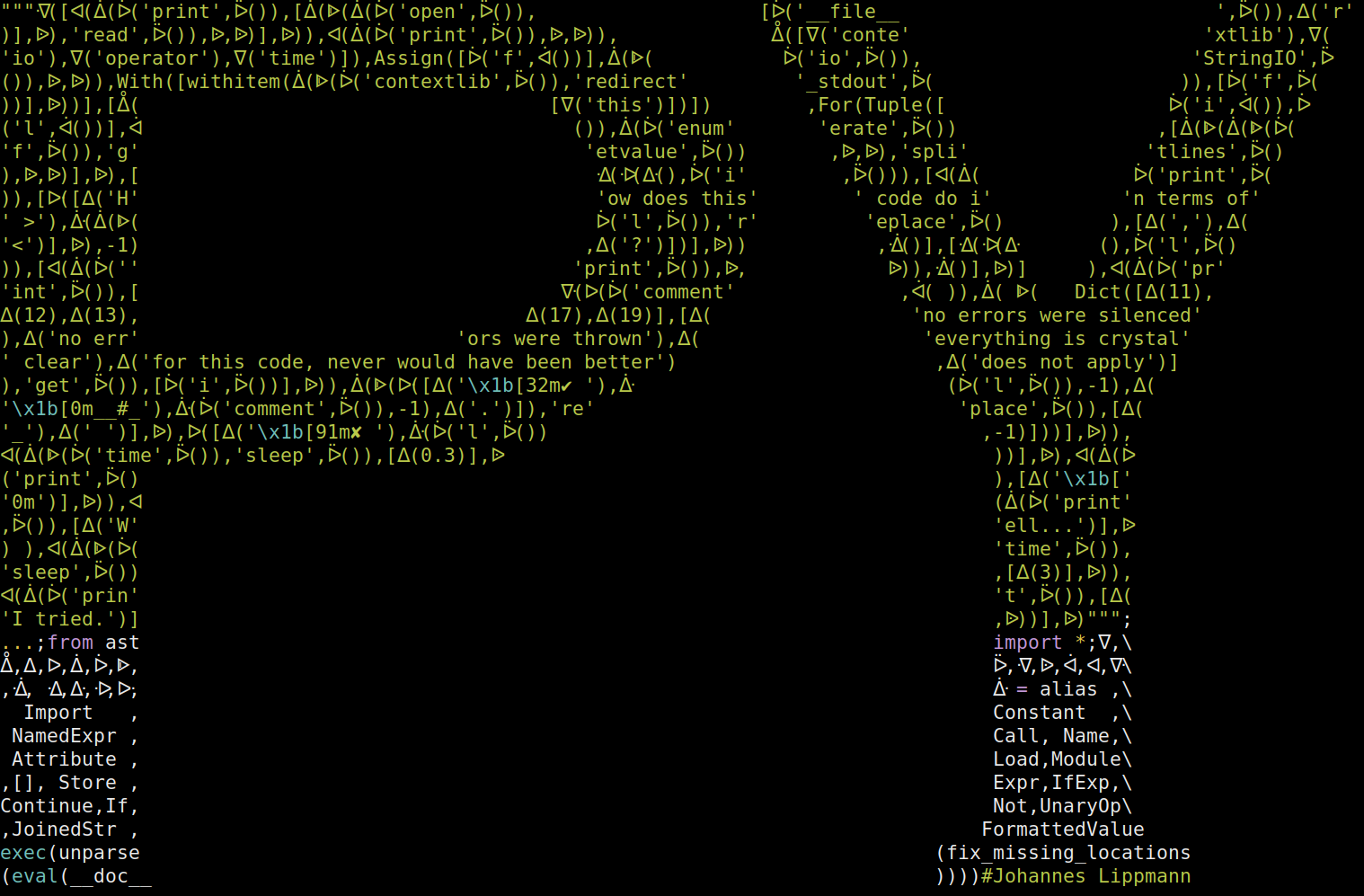
I am a big fan of the “The International Obfuscated C Code Contest” (IOCCC). Their winners page is littered with creative and (in it’s own way) elegant code. Unfortunately I know just enough C to appreciate the code there, I could never write anything like this myself.
…Changelog 2
git showpast
I wanted to write a command-line program that would show you the history of some code within a git repository.
…vcf confusion

The contacts in the address book on your phone can be imported and exported using the vCard format.
This is basically a text file with a .vcf file extention (for virtual contact file).
It is surprisingly readable, here is an example (slightly redacted example from here):
Wie Anfänger an Einfachem scheitern

“Snakes and ladders” ist ein so einfaches Spiel, dass es fast keine Regeln zu erklären gibt:
…changelog
I do a lot of personal computerstuff over the weeks. Most of it ends up in a repository of some sort (if it is not in a repo, have you even done something?) A few things end up in a database, which is fine, too.
…
Do not sort your screws

I used to have a medium-sized toolbox in my basement. Then recently I got my hands onto a relatively big amount of tools. They were not sorted at all.
…Trying out StreetComplete
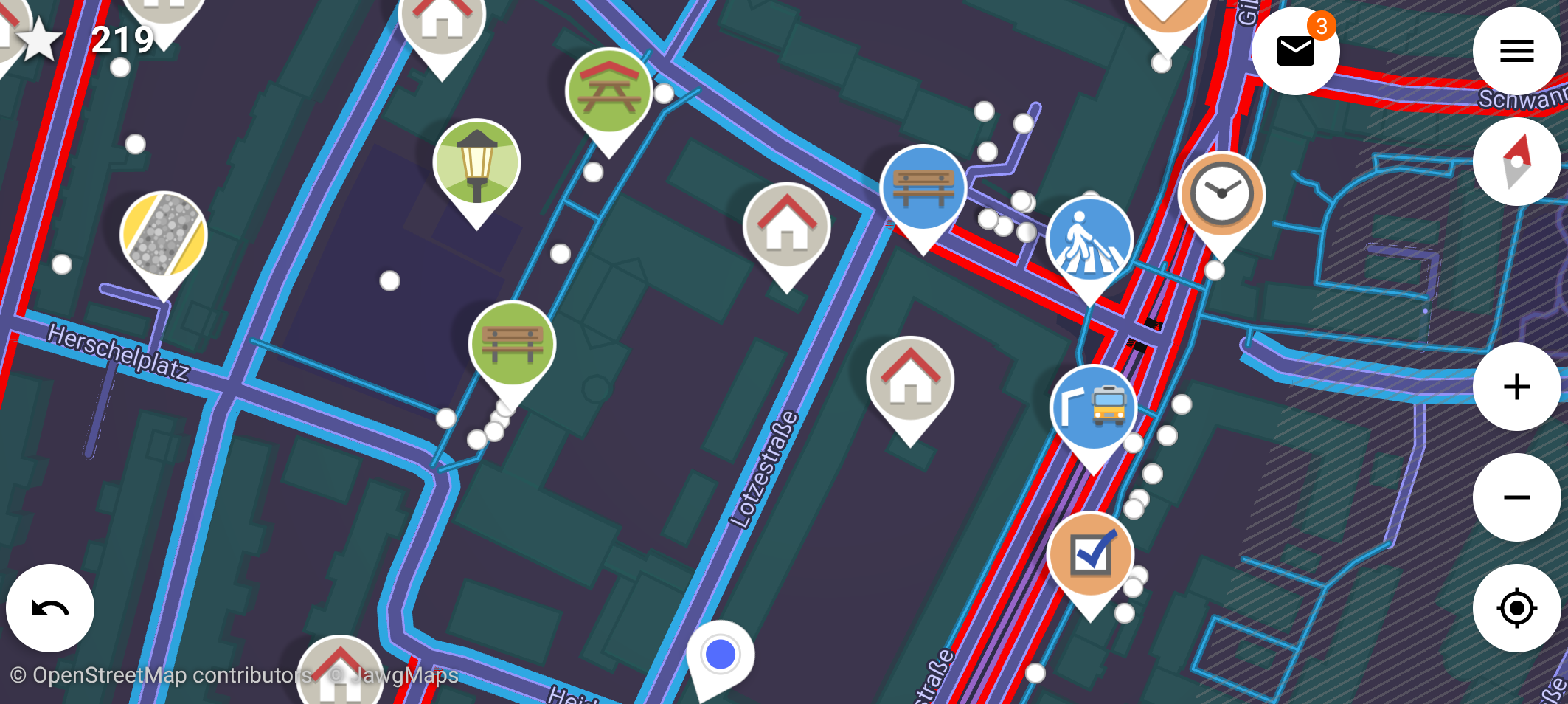
The other day I found that StreetComplete is on F-Droid. I had heard of that app when it came out but had totally forgotten about it. Time to give it a try.
…Annoyed with Sir Arthur Conan Doyle

My wife and I read stories to each other. It is a great way to go to sleep. At some point we started to do the Sherlock Holmes books by Sir Arthur Conan Doyle. A faithful translation of the originals.
…
Hide the tmux statusbar if only one window is used
What?
I want the tmux statusbar to show only if I have multiple tmux-windows open. When only one tmux-window is open, then the status bar should be hidden.
…I quit Social Media

I get addicted to social media quite easily. It doesn’t do me good, I tend to sink a lot of time into it.
…Blogging on mobile

I want to write and publish blog posts from my mobile (which is running Android).
…
How much control over the problem do you have?

There is a problem and a team who should do something about it. That team wants to communicate to others how much control over the problem they have. So they draw a scale, we will call it the problem-under-control-scale.
…Meine Quellen für die Welt der freien Software

Ich komme zur Zeit nicht viel zum schreiben. Dafür gibts gute Gründe, aber manchmal macht es mir etwas aus. Es ist auch nicht so, dass es nichts zu erzählen gäbe, aber die Zeit…
…I wrote a hugo theme
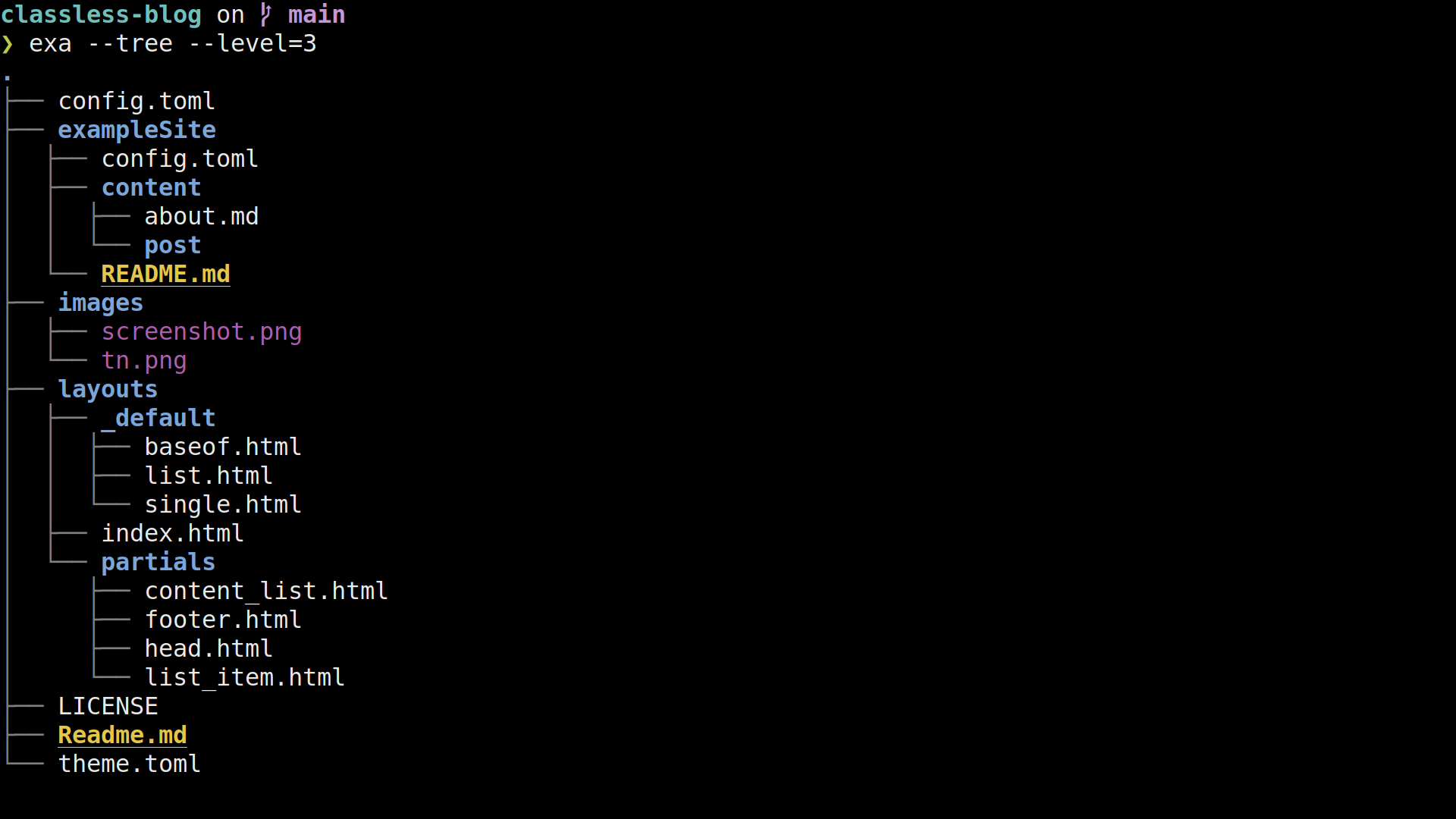
I just love the concept of static site generators (SSG) for websites. They allow to separate content and presentation really cleanly:
…reformat paragraph
Lets say we have a paragraph1 of plain text - probably in a markup language like Markdown, Orgmode, Asciidoc or LaTeX.
…entr should be part of every linux installation
If you use the commandline as your IDE, then entr is super usefull. As most unix programms, it does exatly one thing: “Run arbitrary commands when files change”
…I speak nix now

After living in a love-hate relationship with my nixos-configuration it finally came to the point that it became too big of a file to handle. I already had it versioned (nearly everything I write is versioned). But now the file approached a few hundred lines at I was going to loose my grip on it.
…Proof of concept: Backup from Unix to Nixos with Borg

I want to get a directory backed up with borg on my nixos-server (regulus.fritz.box).
The client may just be a regular unixoid, doesn't have to be nixos (I am using MacOS for testing).
All the commands (unless explicitly stated otherwise) are executed on the client.
Both systems have borg installed.
This is a tutorial, so most explaining will be about what to do, not why to do it.
fun errors

I am currently rewriting Chris Wellons’s racing simulation in rust as a training exercise. His program is really nice in that it is visual, interesting and well under 500 lines of Code - really inspiring. (I wouldn’t have minded speaking variable names and comments though).
…Nix on macOS

Nix is packagemanager like nothing I have seen anywhere else (I have suspicion that Guix goes in a similar direction, but I haven’t tried it out yet). Using it is a bit similar to using a package manager for the first time: Once you have seen the light, there is no coming back.
…

Lies keine Oden, lies die Ausgangsbeschränkungen

Die Ausgangsbeschränkungen (wegen COVID-19) ändern sich ab und zu und haben dann sofort große Auswirkungen auf unser Leben. Deshalb sind dann Zeitungen und Radiosendungen voll mit Diskussionen und FAQs: “Was ist nun erlaubt, was nicht?”
…Sind alle Kreise gleich?
Das Verhältnis von Umfang und Fläche eines Kreises ändert sich mit der Größe des Kreises. Aber sind nicht alle Kreise gleich/kongruent? Sollte dann nicht auch das Verhältnis immer gleich sein? Bei Umfang zu Durchmesser ist es ja auch für alle Kreise gleich.
…First step to NixOS

Given my OS history (Windows -> macOS -> Fedora -> Arch Linux) these were the options I was interested in as a next one:
…Using Newsblur's API

Everybody should have a feedreader for RSS feeds. Lately I decided to subscribe to some feeds of local organisations (like the zoo, some local fablabs or the nearest police station). Things that take place nearby are more interesting after all.
…Rescue data from a Mac that won't start anymore
My wifes macbook didn't start anymore, it tried but went into the same error again and again. This is how I got the data from the old hard drive.
…awk is a language
Most of us know awk as the program that you use when you want only
that one column of your output. Just pipe it through awk '{print
$3}' and the third column you get.
Remark
Die letzten Tage habe ich auf der PyconGermany in Karlsruhe verbracht. Die dominanten Themen waren Machine learning, Docker und vielleicht noch ein bisschen BigData. Über Python2 redet eigentlich keiner mehr, das ist schön.
…
Wieder da

Ich bin wieder da. Der Blog hat lange geruht und jetzt habe ich Lust, wieder zu schreiben.
…Bilder aussortieren

Es gab eine Feier, jemand hat Fotos gemacht und rumgeschickt. Oder vielleicht habe ich selbst hundert mal den selbe Essen fotografiert. Jedenfalls sind da ein Haufen Bilder und ich will nur die guten behalten.
…Hörbücher auf SailfishOS
Unterwegs höre ich sehr gerne Hörbücher - besonders in vollen öffentlichen Verkehrsmitteln, wo man ohnehin nicht viel anderes machen kann als Musik/Podcasts/Hörbüchern zu lauschen oder seinen Feedreeder durchzuarbeiten. Auf SailfishOS gibt es keinen nativen Client, aber die Standardapp “Medien” funktioniert wunderbar. Wie ist also der Workflow?
…Firefox History in der Kommandozeile

Firefox ist so bekannt geworden, weil man alles mögliche an ihm einstellen kann. Warum ist es dann so schwer, ihn von der Kommandozeile zu steuern?
…An der Weboberfläche kratzen

Ich mag Programmieren, aber mit Netzwerk, Browser, Javascript und Webseiten kenne ich mich nicht gut aus. Wenn ich dann einen Fuß ins kalte Wasser halte, ist es schon spannend (für mich). Hier mein jüngstes Erlebnis:
…ping Datenbank
Pingplot war als Vorbereitung für ein etwas größeres Projekt gedacht, für das ich eine Datenbank einsetzen möchte. Also sollte ich erst mal lernen, wie man mit Datenbanken arbeitet.
…Musik hören

Wenn man irgendwann seine Musik gefunden hat, weiß man recht genau was einem gefällt (bei mir ist es Soundtrack Musik). Woher bekommt man die jetzt? Da fallen einem spontan mehrere Wege ein:
…Blogroll
Gewürzrevolver
Der Blog meiner Frau, es geht ums Kochen und Backen. Alle Rezepte haben wir selbst gekocht und probiert und dabei die Fotos gemacht. Und ich hatte sogar mal einen Gastbeitrag.
…Sandsturm

Server haben ist anstrengend und man muss viel Geheimwissen haben. Außerdem funktioniert dauernd was nicht und wenn man mal was austesten will muss man ewige Dokumentation lesen, bis etwas geht. Ich bin schon oft gescheitert.
…Gastbeitrag beim Gewürzrevolver

Ich habe einen Gastbeitrag auf www.gewürzrevolver.de veröffentlicht:
…Going up

5
I I I I I I a I I I a a I a a I a a a I I a a a a a I I a I a I I I I I I I I I I a I a I a
…
{kind=link}
Sane defaults for navigation keys?

When I switched to Emacs, I thought there would be a consistent plan for navigation in a file (or buffer). I thought there would be a key for
…Plotter
Im Mathestudium spielen Plots eine erstaunlich geringe Rolle (man möchte sich davor schützen, aus Bildern falsche Schlüsse zu ziehen). Trotzdem ist es manchmal nützlich/notwendig, es gibt hauptsächlich zwei Anwendungsfälle:
…Emacs lernen, Tag 3, 4 und 5
Emacs lernen, Tag 3
- bin wieder dabei, los gehts
- versuche, einen eingebauten Markdown-Mode zu finden. Es scheint keinen zu geben - wo kann ich Modes kennen lernen? Schau ich später nach, jetzt mach ich noch den Rest vom Tutorial zu Ende.
- Dokumentation zu Befehlen gibt es mit
C-h cfür den Funktionennamen (was oft ausreicht) und mitC-h k BEFEHLfür ein ausführlichere Beschreibung. - Heute komme ich nicht recht vorran, andere Sachen wollen erledigt werden.
- Tutorial ist fertig. Kam nichts Interesantes mehr.
- Was mache ich jetzt? Ich könnte mich wieder mit dem Handbuch beschäftigen. Oder ich schaue mal, welche Modes ich so brauchen könnte.
- Ich schau mal nach Modes. Für Haskell gibt es eine tolle Anleitung , aber die ist so lang, dass ich das nach hinten verschiebe. Erstmal Markdown.
- Ein Markdownpackage ist scheinbar nicht installiert, zumindest finde ich mit
M-xnichts. Auch der Packetmanager findet nichts, das auf emacs und markdown matcht. - Es gibt ein Emacs-Wiki mit einem Eintrag zu einem Markdown Mode. Darin auch ein Link zur Website des Entwickler dieses Moduses.
- Aha, ich soll emacs-goodies installieren. Kein Problem.
- Der Emacs muss neu gestartet werden, damit die Completion den markdown modus kennt. Dann endlich ist es geschaft - ich hab Markdown-Syntax-Highlighting.
- Der Markdown-Modus ist nicht so schmeichelhaft wie ich erhofft hatte. Wenn ich eine Liste mache und enter drücke, muss ich das
*selbst tippen. Das ärgert mich ein bisschen. Immerhin gibt es nur 2 sinnvolle Dinge, die ich dann manchen wollen kann: Die Liste mit einem neuen Element fortsetzten (*) oder die Liste beenden (zwei Newlines).
Für heute muss ich Schluss machen, gibt viel zu tun.
…Emacs lernen, Tag 2
Logbuch, Tag 2
- Starte Emacs mit
emacs -nwwie gestern gelernt. - Starte einen zweiten emacs, um das Logbuch mit zu tippen. Wie bekomme ich jetzt eine neue Datei? Hab keine Ahnung. Behelfe mich schließlich mit
emacs -nw Blogeintrag.mdown. Das geht noch besser. - Weil die Pfeiltasten noch abgeklebt sind muss ich die Shortcuts benutzen um hin und her zu springen. Juhu!
- Bevor ich loslege sollte ich wahrscheinlich lernen, wie man eine Textdatei speichert. Sonst gibts nachher Tränen.
- Speichern geht mit
C-x C-s - Der erste Hammer des Tages: Paste ist nicht, wie erwartet
C-vsondernC-yfür __y__ank (großzügig übersetzt mit zurückreißen). - Yank ist komplizierter als gedacht.
- Der Shortcut für undo (
C-\macht auf amerikanischen Tastaturen mehr Sinn, weil dort das\direkt unter dem Delete Key ist. Mist - ich habe eine Deutsche Tastatur an meinem Laptop und daran wird sich so bald auch nichts ändern. - Lerne ich lieber
C-_dafür, da muss man sich nicht so verrenken. - Undo wird erklärt, aber wie geht redo? Wird hier nicht erklärt, hätte ich aber gerne.
- Warum ist undo eigentlich nicht
C-z? AAAAAAAAAAAAAARrrrrrrgh! Ich wollte es doch nur ausprobieren, nicht den Emacs schließen! Nein! und das letzte mal, dass ich das Logbuch gespeichert habe ist ewig her. - Als ich die Datei wieder öffne und beginnen will, das verlorene wieder einzutippen, erhalte ich eine seltsame Nachricht:

- Gibt es noch Hoffnung für meine Änderungen? Ich tippe
sund der Dialog verschwindet - ohne die erwünschte Wirkung. Mist, das wäre mal ein Feature gewesen das ich brauchen kann. (später lerne ich: Hätte man ins Terminal einfach fg getippt wäre alles ok gewesen. Tja) - Viel zwischenspeichern ab jetzt.
C-x C-sC-x C-sC-x C-sC-x C-s - Ein Bisschen Theorie über Buffer. Alles wo Text drin steht ist ein Buffer.
- Man kann Buffer scheinbar wie Tabs benutzen, nur ohne die Tableiste. Dafür mit
C-x bund dann den Namen von dem Tab eingeben. - Ein File öffnen geht mit
C-x C-f. Das steht angeblich für “_f_ind file”, aber ich merke mir einfach _f_ile. - Mittagspause
- Mir wird erklärt, dass die Datei vorhin nicht wirklcih weg war, sondern “nur in den Hintergrund gerückt”.
C-zist auch eigentlich kein Emacs-Befehl sondern geht direkt an das Terminal, in dem der Emacs läuft. Ich habe noch keinen Überblick über die vielen Schichten der Komplexen Programme, die hier laufen. - Es gibt eine Art Notificationcenter (eigentlich ein Buffer), wo alle eingegangenen Nachrichten (in der unteren Zeile aufgeführt werden. Langsam wird mir klar, warum Leute Emacs als Betriebssystem verstehen.
- Nach dem ich 57% des Tutorials durchlaufen habe wird erklärt, wie man Emacs beendet. Ich habe es ja schon schmerzhaft selbst herausgefunden.
- Die Echo Area (letzte Zeile, wo die Tastencombos angezeigt werden die man bereits getippt hat) hat einen eingebauten Delay. Das finde ich schlecht, sobald ich weiß wie hier alles läuft mache ich den Weg.
- Zwischendurch was trinken, ist ja auch wichtig.
- Jetzt wird es spannend. Es gibt Modes. Für verschiedene Programmiersprachen verwendet man verschiedene Modi, die Dinge verändern (zum Beispiel, wie ein Kommentar aussieht oder was ein Paragraph ist)
- Es gibt Major-Modi und Minor-Modi. Man kann nur einen Major- aber mehrere Minor-Modi gleichzeitig benutzen.
- Ich wechsle sofort vom Fundamental-(Major-)Mode in den Text-(Major-)Mode.
- Fühle mich gleich besser. Es ist gut, wenn der Editor weiß, was ich tue (wenn ich es schon nicht immer weiß)
- Der Minor Mode Autofill nervt eher. Was ich nicht mag, wird nicht benutzt. Ha!
- Ich habe das Gefühl, ein großer Teil der Flexibilität von Emacs wird aus diesen Modes kommen.
- Mein Kopf brummt. Gut dass heute nicht viel los ist.
- Weiter machen: Searching
- Die Incremental search ist genau das, was bei Sublimetext das
Strg-Imacht. Nur nicht fuzzy. - fuzzy search wird überhaupt immernoch viel zu sehr unterschätzt, außer Sublimetext macht das kaum einer richtig.
- Mehrere Frames in einem Fenster. Den Teil überfliege ich nur, von sowas bin ich kein großer Freund. Schön, dass es geht.
- Shortcut des Tages:
<Esc> <Esc> <Esc>als ein all-purpose “get out” command. Das ist gut, denn das drückt man sowieso meistens ganz panisch.
Bilanz, Tag 2
- Diesen Text habe ich im Emacs getippt, Yeah! (und es ist mir nur einmal schief gegangen.
- Das Tutorium habe ich zu 90% durch, sehr gut. Morgen suche ich mir was anderes zum Üben.
- Leider hab ich, als es etwas zu Programmieren gab noch Schwierigkeiten gehabt und dann doch schnell Sublimetext genommen. Ein Moralischer Fehltritt.
- Vielleicht suche ich mir morgen ein paar Modes heraus, die mich beim Schreiben wirklich unterstützen - heute habe ich von ihnen kaum was gemerkt.
Ich freu mich auf morgen.
…Emacs lernen, Tag 1
Auf der Suche nach einem Editor beschäftige ich mit Emacs. Auf Emacs selbst gehe ich später noch genauer ein, hier geht es um meine ersten Kontakte damit.
…Digitaler Haushalt
Wer nach dem Urlaub nach Hause kommt muss erstmal einiges an Haushalt erledigen: Sachen einräumen, den Kühlschrank auffüllen, Wäsche waschen, durchfegen, Blumen gießen, sich bei Nachbarn und Freunden melden und sich um die Post kümmern.
…Editoren
Wer Code schreiben will, braucht einen Code-Editor. Es lohnt sich, sich einen Guten zu suchen, denn man wird viel Zeit mit ihm verbringen und er ist schnell ein essentieller Teil des Computers.
…Meine Configs
Viele Programme besonders unter Unix kann man sogenannten configs (“Konfigurationsdateien”) tunen. Es sind einfache Textfiles, in die man Anweisungen für das Programm aufschreibt und die man dann an eine bestimmte stelle im Dateisystem legt, wo sie das Programm dann auch findet.
…RSS Software
tldr: RSS gehört für mich zu den wichtigsten Bausteinen des Internets. Ich finde jeder sollte davon wissen. Es gibt große Auswahl an guter Software.
…
Bildschirmhelligkeit
(Alles was in diesem Eintrag steht habe ich übrigends von Jonathan Krebs, danke.)
…Computer umziehen
Jetzt sitze ich also für kurze Zeit (meine Freundin steht in den Startlöchern, um den alten abzunehmen) auf 2 Laptops und soll mein Produktivsystem umstellen.
…Schreiben
Wirtschaftsprofessor : "Also wenn Sie einen Text erstellen wollen, dann kommen Sie an den Microsoft Office Paketen nicht vorbei."
Ach so ist das.
Als wir diesen Post in einem sozialen Netzwerk sahen mussten wir alle sehr lachen: Diese Wirtschaftler in ihrer kleinen Microsoft-Welt. So süß.
…Laptop kaufen
Warum?
Für mein Linux Projekt wollte ich einen neuen Computer. Mein treuer Begleiter bisher war ein 13 Zoll MacBook Pro (Early 2011). Der ist auch noch gut, für den Wechsel gab es aber mehrere Gründe:
…Eine Distribution auswählen
Also Linux, na toll. Und da gibt es ja auch nur unendlich viele davon (Statistiken gibts auf Distro Watch). Natürlich kann man auch im Nachhinein wechseln, aber es wäre ja schon gut, wenn man was hätte, wo man sich wohl fühlt. Wie also auswählen?
…Marinieren
TLDR: Seit ich das Fleisch vor dem anbraten noch mariniere hat sich meine Lebensqualität erhöht.
…Webserver
Langfristiges Ziel: So viel wie möglich Infrastruktur auf dem eigenen Server hosten. Dazu sollen gehören
…Woher und wohin
Von Apple…
Ich bin Mathematikstudent. Seit 2011 benutze ich ein MacbookPro und seit 2012 ein iPhone 4S, ich bin gut eingelebt in der Applewelt. Es gibt vieles, was sehr einfach funktioniert, wenn man nur Appleprodukte verwendet. In den letzten Jahren habe ich mir keine Gedanken machen müssen über:
…Auf zu sicheren Ufern
Es wird Zeit, proprietärer Software den Rücken zuzukehren. Endlich. Die Gründe dafür sind einfach:
…